L’apport de l’IA dans l’exploitation du Rapport Mueller

Par Olivier Ezratty, consultant et auteur, notamment de l’ebook Les usages de l’intelligence artificielle (open source, 522 p., novembre 2018).
Publié jeudi 18 avril 2019 par le ministère de la Justice américain, le rapport Mueller était attendu pour déterminer ce qui s’était passé en 2016 et ensuite, autour de l’élection de Donald Trump et d’une possible ingérence de la Russie.
Publié après près de deux ans d’enquête minutieuse, le rapport était « gris » : il dévoilait les relations entre l’équipe de Trump et diverses parties russes, comme les tentatives d’obstruction de ce dernier pendant l’enquête. Mais au bout du compte, aucune inculpation. « No collusion, no obstruction » comme l’a affirmé ensuite à qui mieux mieux le Président.
La coordination implicite entre les Russes et l’équipe de Trump n’était pas suffisamment flagrante pour se faire prendre la main dans le sac : « While the investigation identified numerous links between individuals with ties to the Russian government and individuals associated with the Trump Campaign, the evidence was not sufficient to support criminal charges » (page 9). En gros, les personnages concernés n’ont pas été déclarés coupables, mais on n’est pas vraiment sûr qu’ils soient innocents. Le rapport fait notamment état de conversations via des moyens de communication numériques cryptés qui n’ont pas pu être récupérées, de faux témoignages et d’obstruction des parties prenantes pendant l’enquête, et pas seulement du Président.
L’obstruction est clairement démontrée dans le rapport mais le procureur spécial Mueller n’a pas jugé bon d’inculper le Président car les directives du DOJ ne le permettent pas. Le Président semble donc sorti d’affaire. Mais une quinzaine d’enquêtes se poursuivent, dont l’objet, pour la majeure partie, est encore confidentiel : « In the course of conducting that investigation, the Office periodically identified evidence of potential criminal activity that was outside the scope of the Special Counsel’s authority established by the Acting Attorney General. After consultation with the Office of the Deputy Attorney General, the Office referred that evidence to appropriate law enforcement authorities, principally other components of the Department of Justice and to the FBI. Appendix D summarizes those referrals » (page 12). Le rapport est écrit dans un langage juridique minutieux avec, parfois, des doubles négations ambiguës qui sont complexes à interpréter.
Le rapport Mueller est officiellement téléchargeable au format PDF. Le document fait 448 pages mais il n’est pas « searchable ». Les pages sont en fait fournies en mode « image ». La transparence n’est pas de mise, sans compter les 7,5% de texte noircis car ils concernent des enquêtes encore en cours, des procédés de renseignement inavouables ou des personnes qui ne sont pas inculpées.
Dans « A Technical and Cultural Assessment of the Mueller Report PDF » (avril 2019), la PDF Association critiquait le processus de publication de ce rapport ! En effet, il résulte d’un scan à moyenne résolution (200 dpi) du document imprimé. Le fichier fait 142Mo.

Un rapport scanné pose plusieurs problèmes, notamment celui de ne pas être lisible par des non-voyants via des logiciels de speech to text. Il permet cependant d’éviter des bévues passées comme celle consistant à permettre que le texte en noir soit lisible avec un copier-coller ! La PDF Association rappelle qu’il existe des solutions techniques éprouvées pour produire des documents PDF de qualité, analysables avec des CONTROL-F / rechercher, tout en respectant la confidentialité des zones cachées.
De nombreux médias ont donc passé le rapport « format PDF image » au travers de logiciels de reconnaissance de caractères (OCR) pour le transformer en format PDF dans lequel des recherches sont possibles. Ils s’appuient maintenant couramment sur des réseaux de neurones de deep learning. Mais pas forcément là où on le pense.
Certains développeurs ont ainsi fait de l’OCR du rapport via la bibliothèque Tesseract de Google, qui est un logiciel ancien, issu des années 1980 et ayant régulièrement évolué depuis. Il n’a pas l’air d’utiliser de réseaux de neurones convolutionnels pour analyser les caractères. Il exploite cependant un réseau de neurones à mémoire (LSTM) pour reconstituer des phrases qui se tiennent.
La diffusion de versions propres du rapport est même devenue un véritable business, certaines éditions, même électroniques, étant payantes. C’est ce que raconte The Atlantic dans The Irony of Mueller-Report Profiteering. Le rapport est téléchargeable sur Scribd, mais en échange de vos coordonnées. À éviter ! Pas beaucoup mieux chez Reason, ci-dessous. Enfin, j’ai trouvé une version correcte sans avoir à fournir de coordonnées, sur le site Washingtonian !
Le data journalism s’en est alors donné à cœur joie pour analyser le rapport. Il y a notamment le New York Times qui a dépiauté le texte dans tous les sens, l’a publié (sans PDF) mais en version analysable en ligne avec des commentaires explicatifs de journalistes.
Axios a publié un outil permettant de voir d’un coup d’œil dans quelles pages des termes sont cités. Mais point de véritable IA à l’horizon.
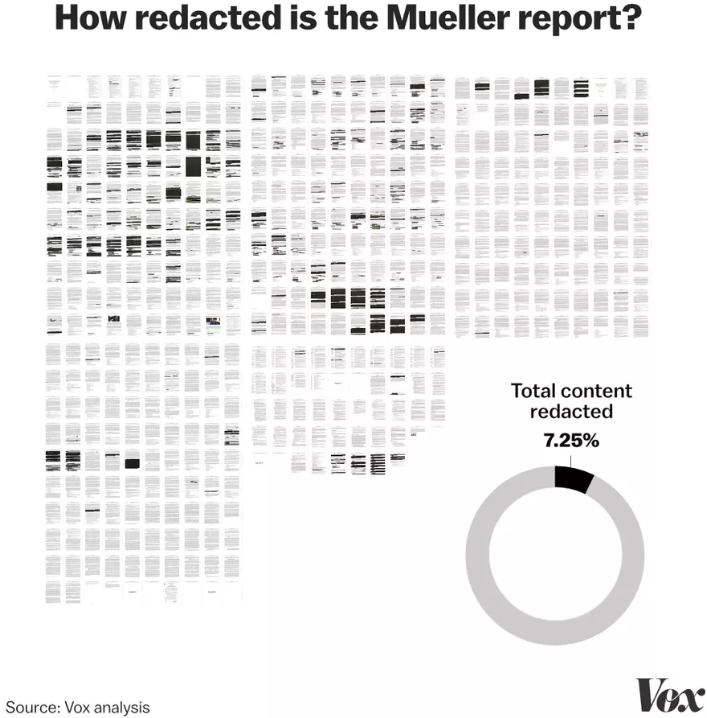
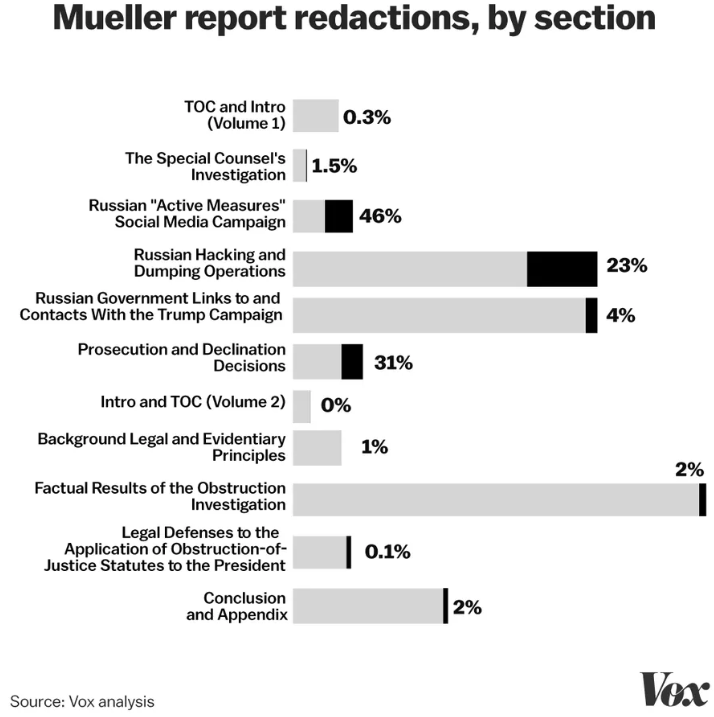
C’est Vox qui est allé le plus loin, avec beaucoup d’extractions de données du rapport pour analyser ce qui était barré, où et sur quel sujet. Ils ont utilisé une méthode basique consistant à exploiter le scan des pages pour évaluer le pourcentage de pixels noirs en en déduire la quantité de textes barrés. Donc, pas d’IA.
« Methodology: We wrote a computer program to turn each page of the report into an image. Then we analyzed each pixel of the image to see whether it was black. Obviously, both the text and the redactions are black, which makes this exercise a bit hard. But we found that a page that is unredacted but full of text is about 3.5 percent black, and a page that is entirely redacted is about 34.5 percent black (because of border and imperfections in the redaction). So we were able to use these baselines to estimate how much each page was redacted. To determine the rationale for redactions, we used a similar method to count the number of times each rationale was used by counting pixel colors — and then double-checked it by going to each page by hand and recounting ».
La meilleure analyse vient de l’avocat et essayiste Seth Abramson, considéré comme un conspirationniste paranoïaque par ses détracteurs, mais qui a vu juste sur un grand nombre de points jusqu’à présent et qui sont très bien décrits dans le rapport Mueller. Son commentaire du rapport était un fil record de 450 tweets publiés en une journée et il ne couvrait que la partie « collusion » du rapport (tome 1). Vous pouvez le consulter grâce au site Threader qui compile des fils de discussion Twitter !
L’IA a pour l’instant joué un rôle fort modeste dans l’analyse de ce rapport et plus généralement autour de la présidence de Donald Trump. La raison en est que l’analyse de textes est un sujet éminemment complexe. Dans le cadre de la politique, elle reste assez basique. Diverses études ont ainsi analysé le champ sémantique du Président, à la fois pendant la campagne électorale de 2016 et ensuite. Il s’agissait surtout d’analyses lexicales et quantitatives.
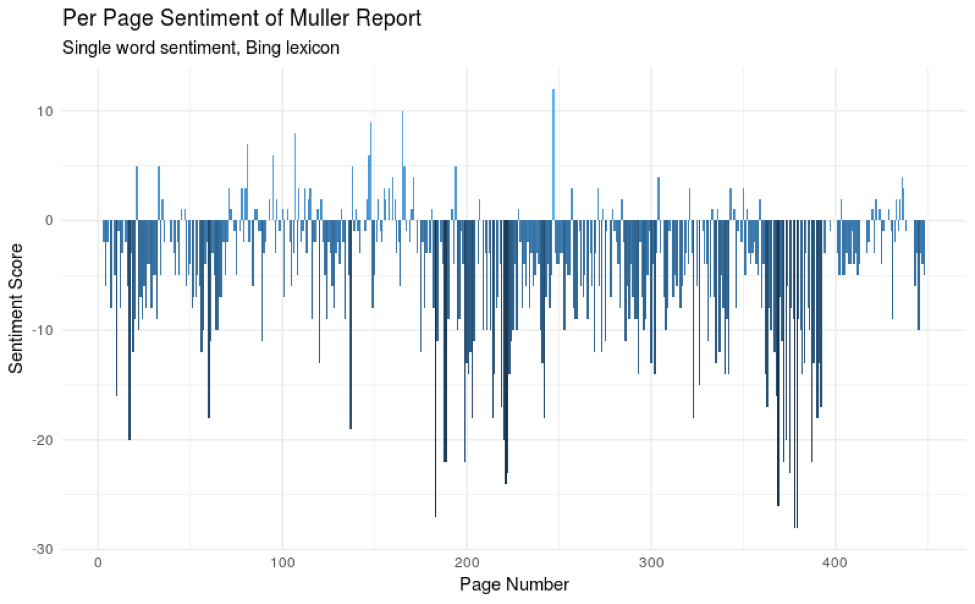
C’est ce qu’ont réalisé des développeurs de Domino Data Labs en publiant un code source R permettant l’analyse syntaxique du rapport Mueller. Ils en ont déduit des analyses sauce big data sur les mots clés et les sentiments exprimés dans le rapport. Le bilan fait ressortir des sentiments plutôt négatifs, ce qui n’est pas une grande surprise (voir le graphe suivant). D’autres graphes et nuages de mots peuvent être générés automatiquement, mais sans que ce qui en ressorte soit exploitable (voir Using R To Analyze The Redacted Mueller Report, 20 avril 2019). Des psychiatres ont même utilisé ces analyses lexicales pour diagnostiquer la panoplie la plus large de pathologies du Président.
L’IA pourrait cependant jouer un rôle dans les phases suivantes d’exploitation du rapport Mueller et des autres documents produits par le Special Counsel. Des techniques à base de traitement du langage permettront peut-être de détecter des tournures de phrases, de comparer les déclarations sous serment avec les dires officiels de la Maison Blanche. Cette comparaison, réalisée manuellement, a déjà permis de démontrer les mensonges de Sarah H. Sanders, la porte-parole de la Maison Blanche. Dans la novlang de la Maison Blanche, « mentir » devient « slip of my tongue ». L’IA pourrait-elle détecter de tels mensonges éhontés ?
Aucune IA ne peut détecter non plus que Cambridge Analytica n’est pas cité dans le rapport, tout du moins hors zones noircies ! On ne saura ainsi rien des liens éventuels entre Cambridge Analytica, les Russes et Wikileaks et de la manière dont le machine learning aurait été utilisé pour influencer les électeurs, surtout dans les swing states de l’élection de 2016.
Un réseau de neurones génératif de type GAN (Generative Adversarial Network) pourrait-il remplir les parties noircies du rapport Mueller ? Probablement pas encore. Des spécialistes du domaine, comme la linguiste Emily M. Bender, ont indiqué que c’était une mauvaise idée et que les données d’entraînement d’un tel système ne sont pas disponibles en quantité suffisante. L’IA ne peut pas faire de miracles ! Mais ce pourrait être tout de même l’occasion de créer quelques parodies ironiques de ses capacités !
I’ve seen several different #NLProc folks suggesting today that it would fun/interesting/worthwhile to use BERT or GPT-2 to fill in the redacted bits of the Mueller report. A short thread on why this is a terrible idea /1
— Emily M. Bender (@emilymbender) 19 avril 2019
L’équipe d’AlgoTransparency détectait que l’algorithme de YouTube recommandait un grand nombre de fois des vidéos biaisées d’explication du rapport Mueller aux audiences américaines, issues de l’agence de propagande russe RT. Voir « YouTube recommended a Russian media site thousands of times for analysis of Mueller’s report, a watchdog group says », par Drew Harwell et Craig Timberg dans le Washington Post du 26 avril 2019. Mais ici, il est plus question d’analyse de données que d’intelligence artificielle.
D’autres enquêteurs pourront faire un décompte quantitatif du nombre de fois où le Président a dénoncé des « fake news » spécifiques qui ont été ensuite vérifiées. Ils pourraient compter par comparaison le nombre de fois où les grands médias ont propagé des rumeurs sur l’enquête de Mueller qui se sont révélées fausses ou non vérifiées.
Des IA bien entraînées peuvent ainsi servir à quantifier des phénomènes et à les rationnaliser. Un peu comme le Washington Post et le New York Times et leur décompte du nombre de mensonges proférés par Donald Trump depuis son accession à la Maison Blanche (9451 mensonges en 800 jours décomptés début avril 2019). Mais peu importe, puisque ce décompte ne change pas la position des citoyens américains qui soutiennent dur comme fer leur Président. Ce n’est plus une question de rationalité à ce stade.
Si l’IA est un outil exploitable en pareille situation, l’intelligence naturelle est largement suffisante pour vérifier ou invalider les faits, associée à des logiciels somme toute assez traditionnels. C’est d’ailleurs elle qui est en déficit aux USA, et aucune IA n’y pourra rien !

