Robot-rédacteur et méta-journaliste, la nouvelle équation gagnante ?

Par @NicolasBecquet, journaliste et manager des supports numériques de L’Echo, quotidien économique et financier belge. Billet invité
Lors des élections départementales françaises, en mars dernier, Le Monde a inauguré une utilisation massive de la Génération Automatique de Texte (GAT) pour couvrir les résultats de 30.000 communes et 2.000 cantons. Mais si cette pratique fait figure de nouveauté sur le web français, elle fait déjà partie du quotidien de certaines rédactions américaines, et il est fort probable que de nombreux journalistes français aient déjà été en contact avec une dépêche Associated Press rédigée automatiquement.
Si le journalisme n’est pour l’instant qu’un domaine marginal d’application de la génération automatique de texte, les perspectives sont prometteuses face à la montée en puissance du ciblage et la personnalisation de l’information.
Laurence Dierickx est développeuse numérique, elle s’apprête à défendre un mémoire consacré la question. Passée par la case journalisme, elle défendra en juin ses travaux sur « la génération automatique de textes dans un contexte journalistique » dans le cadre d’un master en Sciences et technologies de l’information et de la communication (MASTIC), à l’Université Libre de Bruxelles.
ENTRETIEN :
La GAT existe depuis de nombreuses années, mais elle ne fait débat que depuis qu’elle concerne le journalisme…
« Les origines de la génération automatique de textes en langue naturelle remontent aux années 1960 et le monde de la recherche a largement contribué à son développement et à son essor. En 1985 déjà, une chercheuse française, Laurence Danlos, avait déjà mis au point un système de génération des dépêches.
Les systèmes de GAT (NDLR Génération Automatique de Texte), qui sont en fait plutôt des logiciels que des robots, sont capables de produire de grandes quantités de textes à partir de données brutes, principalement financières et économiques.
L’un des premiers systèmes de génération, utilisé de manière opérationnelle, s’appelle FoG : c’est un générateur de prévisions météorologiques, né au début des années 1990. Peu à peu, les systèmes se sont diversifiés et ont été utilisés dans une variété de secteurs pour une palette de finalités très variées : des notices pour arrêter de fumer, des rapports médicaux, des manuels d’utilisation ou encore la description de produits commerciaux. Mais avec l’arrivée de la GAT sur le terrain de la presse, on touche à une profession qui traverse une crise d’identité liée au développement des usages et des pratiques en ligne. A cela, s’ajoute un contexte économique assez difficile. »
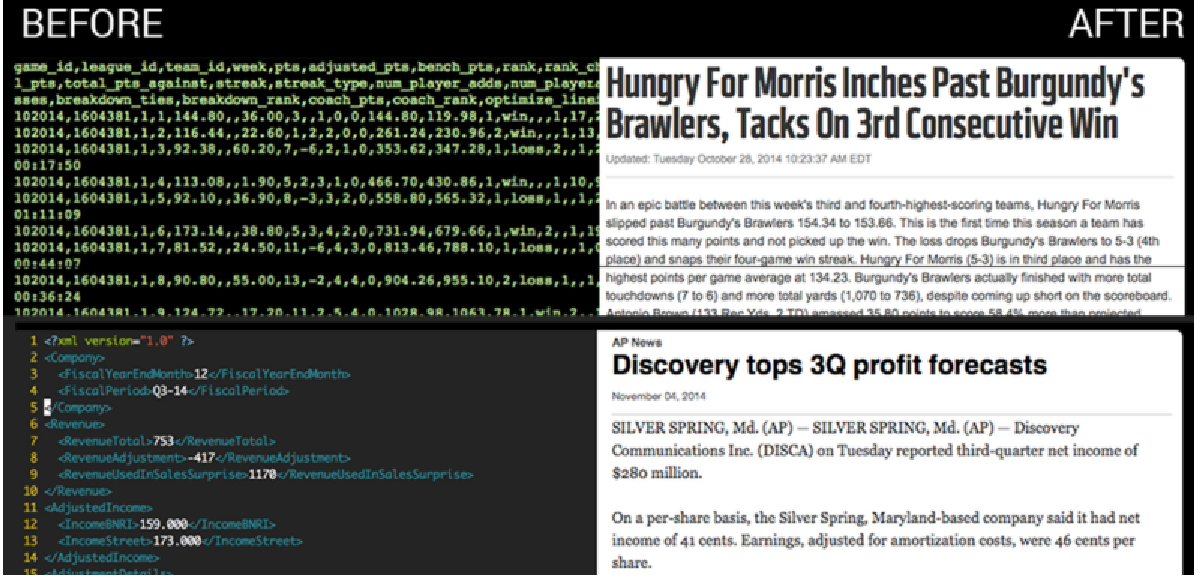
Plus d’un milliard de textes ont déjà été produits, c’est énorme.
« Les deux sociétés qui occupent le marché des médias aux États-Unis, Automated Insights et Narrative Science, ont une capacité de production prodigieuse : la première annonce sur son site un milliard de textes produits en 2014, à un rythme de 2.000 productions à la seconde.
Leurs clients média sont des clients parmi d’autres. On retrouve notamment le magazine économique Forbes, qui fait appel à Narrative Science et sa solution Quill.
Depuis juillet 2014, Automated Insights est partenaire de l’agence de presse Associated Press, avec Wordsmith, pour des dépêches économiques (traitement de bilans trimestriels d’entreprises) et des comptes rendus de rencontres sportives étudiantes. La particularité de ces sociétés est de répondre à une demande croissante en contenus, en occupant aussi des espaces qui ne l’étaient pas jusqu’à présent, faute de moyens et peut-être aussi d’intérêt. »
Dans votre mémoire, vous mettez en lumière que les principaux freins à la GAT ne concernent pas tant la technologie que la qualité des données traitées.
« Sans données de qualité, pas de génération de qualité : c’est pourquoi les sociétés sont très attentives à leur contrôle et à la gestion des erreurs. C’est la base de leur travail.
La question de la qualité des données pose surtout problème lorsque l’on fait appel à des bases de connaissances tierces, comme les données publiques ouvertes, qui peuvent apporter des informations de contexte. Une génération de type journalistique nécessite des données à jour, ce qui n’est pas toujours le cas dans ce type de données.
Pourquoi ? Parce qu’une donnée n’est pas figée une fois pour toutes, elle est susceptible d’évoluer avec le temps. Cela nécessiterait un travail de suivi quasi permanent pour les maintenir à jour. Dans l’open data public, cette question est problématique, car elle suppose des moyens humains et financiers que les administrations ne dégagent pas forcément. La chercheuse Isabelle Boydens souligne aussi que ces données prolifèrent dans l’environnement non contrôlé d’internet : leur qualité est donc potentiellement douteuse. »
Vous faites une distinction entre « journalisme automatique », « journalisme de données » et « assisté par ordinateur », quelles sont les différences ?
« J’ai utilisé la typologie de Coddington, que je trouve très pertinente pour catégoriser les différentes approches par données du journalisme.
-
Le journalisme assisté par ordinateur s’appuie sur les outils informatiques pour nourrir l’investigation journalistique, et ses origines remontent à la fin des années 1960.
-
Dans les années 2000, le journalisme de données a fait émerger de nouveaux profils journalistiques aux États-Unis, dans la mesure où la manipulation de données donne souvent lieu à des productions interactives.
-
Le journalisme computationnel va un cran plus loin en combinant algorithmes, bases de données et méthodes des sciences sociales. »
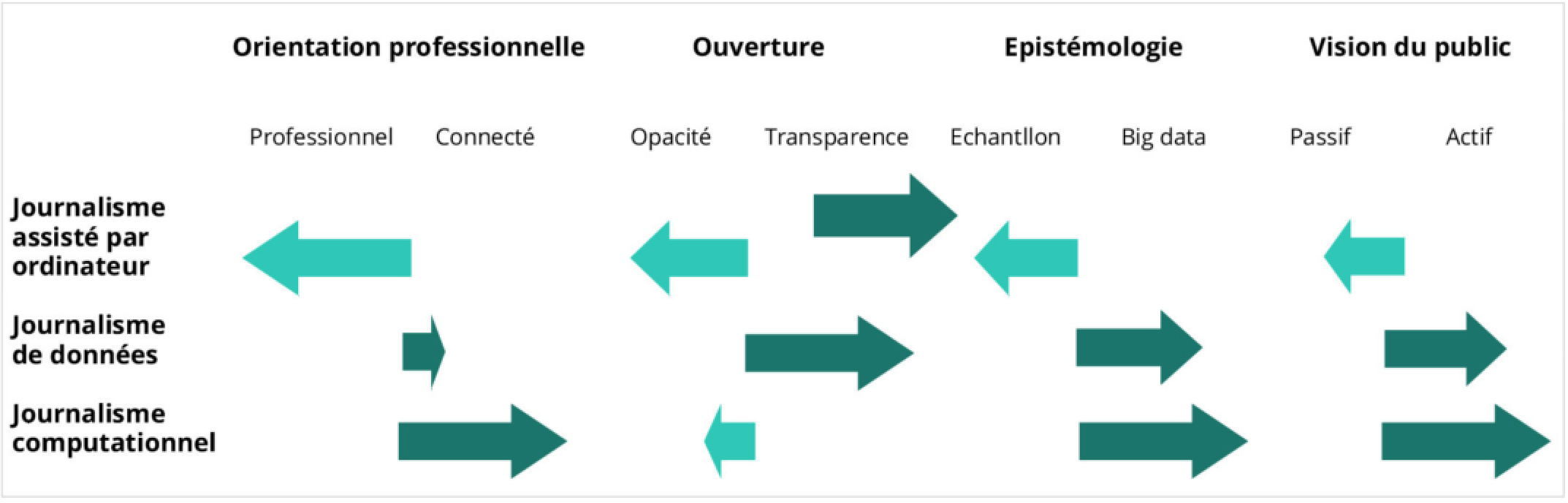
Coddington considère que les deux premières approches sont plus ouvertes et transparentes, à l’inverse du journalisme computationnel qui est considéré comme plus opaque. Il « range » le « journalisme automatique » dans cette catégorie – ce qui est toutefois discutable, sur le plan théorique.
Ces deux dernières approches ne correspondent pas aux compétences traditionnellement liées à la pratique du métier : ce qui a très bien été compris aux États-Unis où on a commencé par intéresser les informaticiens au journalisme, faute d’avoir pu réussir l’inverse.
Aujourd’hui, il existe plusieurs masters en journalisme computationnel, qui est devenu une vraie spécialisation dans le monde anglo-saxon, et on y apprend aussi le « journalisme automatique ».
Vous concluez que la GAT peut instaurer un nouveau rapport homme-machine, dans quel sens ?
« Les témoins sollicités et les sources analysées convergent dans le même sens : celui de faire des machines des alliées plutôt que des adversaires, en leur confiant des tâches répétitives et chronophages qui permettent aux journalistes de dégager du temps pour l’enquête et le reportage.
C’est d’ailleurs dans cet esprit que l’accord entre Automated Insights et Associated Press a été conclu. Toutes les dépêches n’y sont d’ailleurs pas entièrement automatisées : l’analyse de certaines sociétés nécessite des informations de mise en contexte dans le traitement de leurs bilans financiers, et cette tâche est confiée aux journalistes. La GAT donne aussi l’occasion de se repencher sur la valeur ajoutée du journaliste et sur la nécessité démocratique de la cultiver. »

data2content-syllabs
La GAT alimente les spéculations sur la théorie de « la fin du travail« . Fantasme ou réalité pour le futur des rédactions?
« Depuis l’essor du World Wide Web, les discours les plus pessimistes circulent sur la fin du journalisme. Voilà qui fait farine au moulin alors que rien ne permet d’affirmer que la GAT fait perdre leur emploi aux journalistes américains.
La GAT peut appuyer le travail journalistique, à condition de ne pas être traitée par les éditeurs comme une nouvelle forme de journalisme bon marché. On ne peut pas non plus affirmer qu’il n’y a pas de risque zéro pour l’emploi. Mais vu le contexte – un métier souvent précaire, dans lequel il est de plus en plus difficile de faire carrière, et où le nombre de candidats à l’emploi est disproportionné par rapport au nombre de places disponibles – les craintes sont compréhensibles.
Par ailleurs, ING a publié récemment une étude prospective sur l’impact de l’automatisation sur l’emploi. On y constate que les journalistes n’y sont pas les plus menacés ».
Des études ont été menées sur la manière dont sont perçus des articles générés de manière automatique. Avantage au robot-rédacteur ?
« Deux recherches ont été menées récemment en Suède et aux Pays-Bas. Celle de Clerwall montre que les articles générés présentent plusieurs qualités (objectivité, fiabilité, cohérence…) mais qu’ils sont moins plaisants à lire, plus ennuyeux, moins bien écrits. Elle montre aussi que les lecteurs ne font guère de différence entre les articles générés par des logiciels et ceux rédigés par des humains. L’étude de Krahmer et van der Kaa conclut également que la perception est identique pour les deux types de textes ».
Humour, ton, angle, style, autant de paramètres déjà disponibles pour personnaliser l’écriture.
« Après la question du paramétrage, il s’agit surtout d’une succession de choix qui s’opère au sein d’un processus modulaire. Plusieurs phases de transformation linguistique s’y succèdent. Elles vont permettre de transformer des données structurées (aux formats JSON, XML…) en phrases construites et intelligibles par un humain. Ce processus répond à deux questions : « Quoi dire ? » et « Comment le dire ? ».
Les deux sociétés américaines, actives depuis le début des années 2010, sont assez fortes dans la variété de types de récits qu’elles proposent. Pour Robbie Allen, fondateur d’Automated Insights, « the sky is the limit ». Cependant, il existe tout de même une limite aux récits générés : tout ce qui relève de la critique, du commentaire, de l’opinion et du sentiment humain. »
Justement, quelle est la place pour l’humain, pour le journaliste, dans la procédure de la GAT?
« L’humain a sa place dans ces processus et son rôle varie d’une société à l’autre. Chez Narrative Science, ils font appel à des méta-journalistes (ou méta-écrivains) qui définissent le cadre du récit. Chez Syllabs, ce sont des ingénieurs-linguistes qui paramètrent le système Data2Content. Le paramétrage est, bien sûr, fonction du domaine d’application. C’est ce qui explique pourquoi il n’est pas possible de tester ces systèmes en direct.
Un danger pourrait consister dans l’introduction de biais lors des paramétrages et, en la matière, on n’est pas si éloignés des biais pouvant être induits par des choix éditoriaux. Le contrôle doit donc se faire en amont de ces systèmes et certains, comme le journaliste Tom Kent, plaident pour une éthique du « robot journaliste »« .
Dans votre mémoire, vous affirmez qu’il y a une différence d’approche entre les firmes américaines et la française Syllabs.
« Oui, dans la mesure où les technologies américaines s’appuient sur des systèmes experts qui relèvent du machine learning, un des champs de l’intelligence artificielle. Ce sont des systèmes très complexes qui reposent sur un apprentissage automatique. Ils sont souvent qualifiés de boîtes noires. Data2Content consiste en un système à base de règles, c’est assez différent. Mais c’est un fait, il est difficile de savoir exactement comment fonctionnent ces programmes informatiques, secret industriel oblige ».
Entretien réalisé par Nicolas Becquet
Aller plus loin :
- Algorithmes et journalisme, questions et enjeux
- Le journalisme automatique
- Affinités prédictives : des algorithmes et des hommes